On a rainy day here I wondered exactly when I should book a ticket up to Durham for another term. Most of the booking websites will help you, but not much: it’s tiresome to check a few days to see what the price variation is—and it can be fairly enormous. I was also curious as to what the long term trends might be: they don’t just seem to go down. All of which suggested some code to screenscrape all the tickets from somewhere and analyse them. It seems the national rail website encodes the query straight into the url (though not as an http query) and then sticks the results, in json, in the page served, presumably for some javascript to parse later. So all we need is to generate the url:
def generate_url(depart, destination, when, departing=True):
"""Generate a url to search nationalrail's database with. Parameters
are:
* depart: 3-letter station departure code
* destination : 3-letter station arrival code
* when: datetime.datetime object for departure date/time
"""
if departing is True:
da = "dep"
else:
da = "arr"
url = "http://ojp.nationalrail.co.uk/service/timesandfares/%s/%s/%s/%s/%s" % (
depart, destination, when.strftime("%d%m%y"), when.strftime("%H%M"),
da)
return (url)
And then parse it. I’d never done a parser before, but BeautifulSoup makes it easy enough:
for i in soup.find_all('td', class_='fare'):
i = i.script.contents[0]
data = json.loads(i.strip())
Where ‘soup’ is a BeautifulSoup.parser() instance we’ve fed the downloaded
html into. The class for the table elements is clear enough from
reading the downloaded html. Then we do some (not brilliantly elegant)
munging of the data to generate an OrderedDict by day of OrderedDicts
of all of the trains for that day. I’m only an occasional coder and
tend to reinvent the wheel, as the code probably shows. But it works
as expected (until the website changes).
Parallel and Queueing
Maybe it’s just the internet here, but downloading is slow. So slow I envisaged keeping a database and comparing randomly selected trains to see if the online data had changed, and only then re-profiling. Then I thought of doing it in parallel, and had a look at a few tutorials. It seems that real coders know a lot about queueing (or queuing, I can’t decide), and that my first idea—hard-code four different worker functions, divide the days up between them, and then have them run until finished, and then order the results—was really too much like silliness, merely because I’ve never written a class before. So here is my first OOP, loosely modified from someone’s example code:
class ThreadProfileTrains(threading.Thread):
def __init__(self, train_queue):
threading.Thread.__init__(self)
self.train_queue = train_queue
# print some stuff to stay we started
print('Begun thread')
self._open = True
def run(self):
global all_fares
while self._open:
# Grab a train from train_queue.
train = self.train_queue.get()
# And process it.
all_fares[train['date']] = linear_profile_days(
train['depart'],
train['destination'],
train['date'],
search_days=0)
# Mark the train_queue job as done.
self.train_queue.task_done()
def close(self):
print("Closing", self)
self._open = False
That was surprisingly painless, and I can almost read it. Maybe I should finally learn some object-oriented stuff (I mainly write scripts to make daily tasks easier, and it’s always seemed overkill). Anyhow, then we just populate the queue and start the threads:
train_queue = queue.Queue()
for day in range(search_days + 1):
date = start_date + timedelta(days=day)
train_queue.put({
'depart': depart,
'destination': destination,
'date': date
})
threads = [
ThreadProfileTrains(train_queue) for _ in range(parallel_threads)
]
for t in threads:
t.setDaemon(True)
t.start()
…and wait for it to finish. There’s got to be a neater way to sort than this, but this is what came to me (a little knowledge is dangerous):
train_queue.join()
for t in threads:
t.close()
global all_fares
ordered_dates = sorted(list(all_fares.keys()))
trains = OrderedDict()
for d in ordered_dates:
trains[d] = all_fares[d]
At that point we’ve written most of the functions (see the source,
below), and just need to plot, which is easy with pyplot, and manage
args, which is even easier with argparse (after years of drowning in
optarg whenever I need to I can finally add arguments painlessly).
And we can download in no time (I limited the threads to 5 to be kind,
but it’s still fast), plot and zoom around; for more information, save
to csv, open in a spreadsheet and use standard data manipulation
tools. Now you know when to travel:
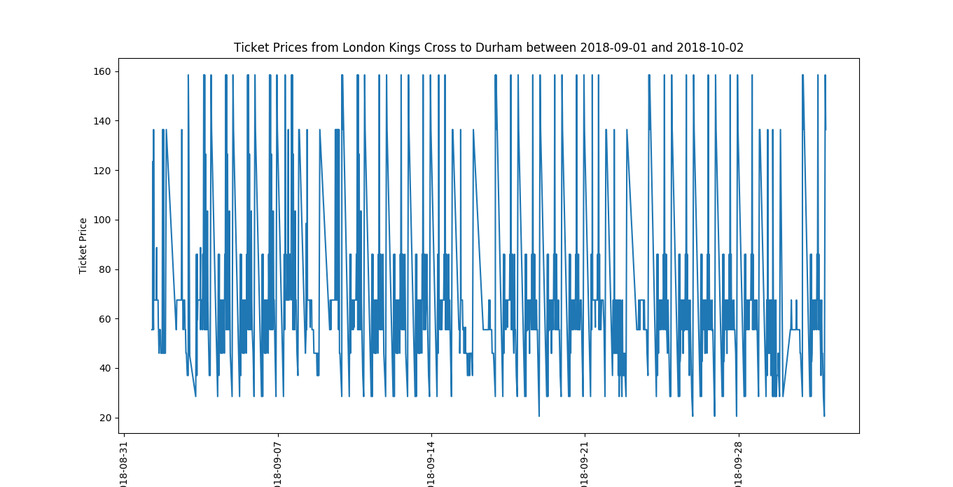 Much clearer than online! Code—if you want a laugh—is over at
gitlab.
Much clearer than online! Code—if you want a laugh—is over at
gitlab.
(Update: the code is a risable as ever, but I added a very basic gui at the request of my father. If anybody’s interested, email me and I’ll clean the code up and put it on Pypy.)